מבחני t הם מבחנים סטטיסטיים שמשמשים להשוואת שני ממוצעי מדגם או השוואה של ממוצע מדגם בודד לממוצע האוכלוסייה. מבחנים אלו נמצאים בשימוש נרחב במחקרים ומשתמשים בהם לרוב על מנת לקבוע האם קיים הבדל מובהק בין שתי קבוצות.
מבחני t נקראים על שם התפלגות t, המשמשת לחישוב ההסתברות לקבלת ערך t מסוים. אנו נשתמש בהתפלגות t כאשר סטיית התקן של האוכלוסייה, סיגמה, אינה ידועה לנו. התפלגות t דומה מאוד בצורתה להתפלגות הנורמלית שאנחנו מכירים, אבל יש לה זנבות מעט "עבים" יותר. זאת אומרת, בהתפלגות t ישנם יותר ערכים קיצוניים מכיוון שהיא מבוססת על מדגם קטן יותר, מה שהופך אותה לפחות מדויקת. בתמונה למטה, תוכלו לראות את ההבדל בין התפלגות Z להתפלגות t בדרגות חופש (n-1) וגדלי מדגמים שונים:
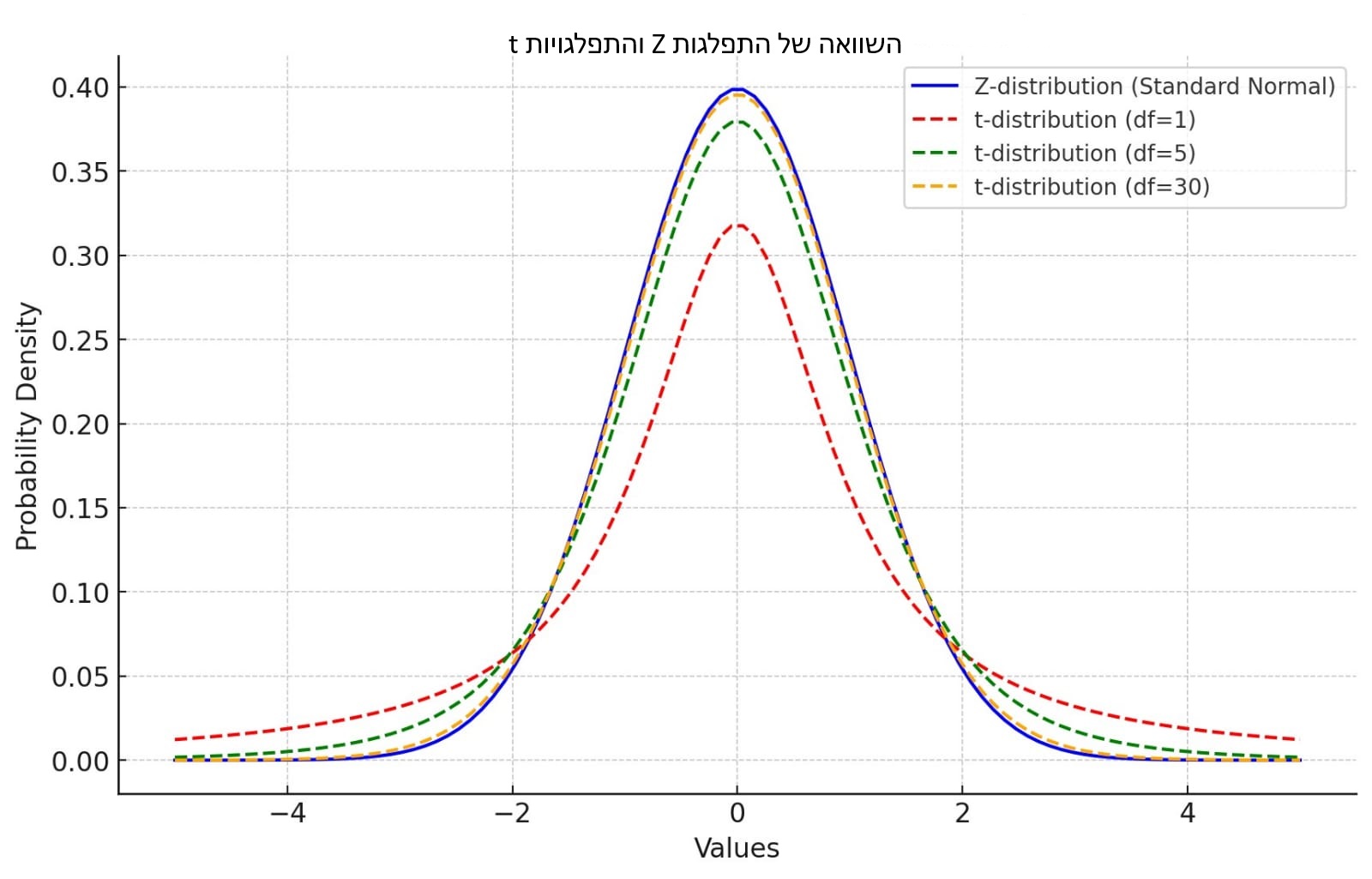 כמו שאתם רואים, ככל שדרגות החופש (אשר מושפעות מגודל המדגם) הולכות ועולות, כך התפלגות t הולכת ודומה בצורתה להתפלגות Z. למעשה, אפשר להסתכל על התפלגות Z כעל התפלגות t עם אינסוף דרגות חופש (גודל מדגם של אוכלוסייה).
כמו שאתם רואים, ככל שדרגות החופש (אשר מושפעות מגודל המדגם) הולכות ועולות, כך התפלגות t הולכת ודומה בצורתה להתפלגות Z. למעשה, אפשר להסתכל על התפלגות Z כעל התפלגות t עם אינסוף דרגות חופש (גודל מדגם של אוכלוסייה).
במבחני t למדגם בודד, אנו משווים ממוצע מדגם יחיד לממוצע ידוע של האוכלוסייה ובודקים באמצעות מבחן לבדיקת השערות האם הפער ביניהם הוא מובהק.
חישוב טעות התקן
בשאלות קודמות, תמיד סטיית התקן של האוכלוסייה, סיגמה, הייתה נתונה לנו והשתמשנו בה על מנת לחשב את סטיית התקן של התפלגות הדגימה, או במילים אחרות – את טעות התקן. אבל בפועל, המצב במציאות הוא מאוד שונה: סטיית התקן של האוכלוסייה כמעט אף פעם לא ידועה לנו. ולכן על מנת שנוכל לחשב את טעות התקן, אנו נשתמש בנתוני המדגם כדי לאמוד או להעריך את השונות של האוכלוסייה. במבחן t למדגם בודד שבו אנו משווים את ממוצע המדגם לממוצע ידוע באוכלוסייה, אנו נשתמש בנוסחה הזאתי:

ניתן לראות שהנוסחה מאוד דומה לנוסחה שאנו מכירים ולמדנו בסטטיסטיקה א' לחישוב השונות עם הבדל אחד קטן במכנה. מכיוון שאנחנו אומדים את השונות של האוכ' ולא משתמשים בשונות האמיתית, אנחנו למעשה מחלקים בn-1 ולא בn, שזה למעשה דרגות החופש. דרגות חופש מתייחסות למספר הערכים שיכולים או חופשיים להשתנות. תחשבו למשל על קבוצת אנשים שמנסה לבחור מאיזה מקום להזמין פיצה. אם קיימות N מסעדות, וכולם חופשיים לבחור איזו מסעדה שהם רוצים, אז ישנן N דרגות חופש. עם זאת, במידה ואדם אחד כבר החליט על מסעדת מסוימת, אז ישנן כעת רק N-1 דרגות של חופש . לאחר שנחשב את האומד לסטיית התקן של האוכלוסייה באמצעות שימוש בנתוני המדגם, אנו נציב בנוסחה לחישוב ציון התקן הסטטיסטי של t:

את הערך הסטטיסטי אנחנו נשווה לערך קריטי מטבלת t. הטבלה הבאה לקוחה מדף הנוסחאות של האוניברסיטה הפתוחה, אך של רוב המוסדות הטבלה דיי דומה והעיקרון זהה:

בחלק העליון (באדום) אנו נסתכל על רמת המובהקות שנדרשנו אליה בשאלה (בד"כ 5%). ובחלק השמאלי (בכחול), נסתכל על דרגות החופש המתאימות (n-1). כאשר נצליב את המידע משני המקומות הללו, אנחנו נקבל את הערך הקריטי המתאים. למשל, ברמת מובהקות של 5% עבור מדגם של 20 אנשים, אנחנו נסתכל על אלפא שווה 0.05 ו19 דרגות חופש, ונראה שהערך הקריטי המתאים הוא 1.746:

כמו במבחן זד, גם כאן יש לנו השערות חד-זנביות והשערות דו זנביות. גם כאן ההשערה החד זנבית מתחלקת להשערה חד זנבית ימנית, והשערה חד זנבית שמאלית. השערה עם זנב שמאלי קובעת שממוצע המדגם נמוך משמעותית מ-ממוצע האוכלוסייה, וסט ההשערות ייכתב כך:
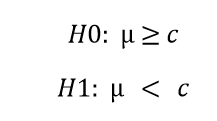
* כאשר C יהיה ערך הפרמטר לפי השערת האפס.
בהשערה עם זנב שמאלי, כאשר סטטיסטי המבחן יהיה קטן יותר מהערך הקריטי, אנו נמקם אותו באזור הדחייה ונדחה את השערת האפס.
השערה ימנית, לעומת זאת, קובעת שממוצע המדגם יהיה גבוה משמעותית מ-ממוצע האוכלוסייה ועל כן סט ההשערות יראה כך:
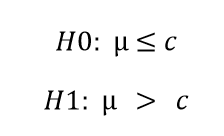
בהשערה עם זנב ימני, כאשר סטטיסטי המבחן יהיה גדול יותר מהערך הקריטי, הוא ימוקם באזור הדחייה ונדחה את השערת האפס.
השערה דו-זנבית אינה מתחייבת לגבי כיוון ספציפי בנוגע לממוצע המדגם בהשוואה לממוצע האוכלוסייה. במקום זאת, בהשערה דו זנבית, החוקר בודק האם ממוצע המדגם שונה באופן מובהק מ-ממוצע האוכלוסייה בכל כיוון שהוא. וסט ההשערות ייראה כך:
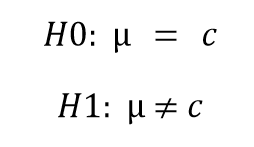
בהשערה דו זנבית אנחנו נחצה את רמת המובהקות, מה שיקשה על החוקר לדחות את השערת האפס. בהשערה דו זנבית, כאשר ערך סטטיסטי המבחן t יהיה גדול מהערך הקריטי העליון או קטן מהערך הקריטי התחתון , אנו נמקם אותו באחד מאזורי הדחייה ונדחה את השערת האפס. מאחר והשערה זו אינה "מתחייבת" לאף כיוון, כמו בפעמים קודמות, אנו נחצה את רמת המובהקות עבור כל אחד מאזורי הדחייה.
השערת האפס (H0): זמן המענה הממוצע אינו גדול מ-3 דקות. או במונחים סטטיסטיים µ=3
השערת החוקר (H1): זמן המענה הממוצע גדול מ-3 דקות. או µ > 3
רמת המובהקות הנתונה בשאלה היא 0.05
 חישוב האומדן לסטיית התקן של האוכלוסייה, S כובע:
חישוב האומדן לסטיית התקן של האוכלוסייה, S כובע:

נחשב באמצעות הצבה בנוסחה הבאה:

הצבה:

על מנת לקבוע אזורי דחייה וקבלה, עלינו למצוא ראשית את הערך הקריטי בטבלת t לפי 9 ד"ח (בכחול) ורמת מובהקות של 0.05 (באדום), הערך הקריטי הוא 1.833 (בסגול). מכאן אנו מבינים שהערך הסטטיסטי גדול מהערך הקריטי ולכן ימוקם באזור הדחייה של השערת האפס:

בסוף הפתרון, לאחר שכתבנו את כל החישובים, אנו נכתוב את המסקנה שלנו: מכיוון שהערך הסטטיסטי גדול מהערך הקריטי , הוא ימוקם באזור הדחייה של השערת האפס. לפיכך, ברמת מובהקות של 5%, נוכל לדחות את השערת האפס ולהסיק שזמן המענה הממוצע באוכלוסייה גדול באופן מובהק מ-3 דקות.
כדי לבחון את ההשערה שציון הדיוק הממוצע של מודל הבינה המלאכותית שונה באופן משמעותי בין שתי שיטות האימון שונות, עלינו לבצע מבחן t למדגמים בלתי תלויים.
השערת אפס (Ho): ציון הדיוק הממוצע של מודל הבינה המלאכותית זהה בין שתי שיטות אימון שונות.
µ1-µ2=0
השערת החוקר (H1): ציון הדיוק הממוצע של מודל הבינה המלאכותית שונה באופן משמעותי בין שתי שיטות אימון שונות.
µ1-µ2≠0
נחשב את ממוצעי המדגם ואת האומדן לסטיות התקן עבור כל שיטת אימון.
עבור שיטת אימון א':
ממוצע מדגם:

אומדן לשונות המדגם:

עבור שיטת אימון ב':
ממוצע מדגם:

אומדן לשונות המדגם:

כעת נוכל לחשב את השונות המשותפת של שני המדגמים יחד באמצעות שימוש בנוסחה הבאה:

נציב:

כעת נוכל לחשב את ה-t סטטיסטי :

כאשר n1 ו-n2 הם גדלי המדגם עבור כל שיטת אימון. ובמכנה אנחנו מציבים את השונות שחישבנו עבור כל מדגם.
נציב:

באמצעות טבלת התפלגות t עם 28 דרגות חופש (n1 + n2 – 2) ברמת מובהקות של 0.05 דו זנבית (שזה שווה ערך לרמת מובהקות 0.025 חד זנבית), אנו נראה שערך t הקריטי הוא ±2.048:

מכיוון שערך ה-t המחושב נמצא מחוץ לטווח ערכי ה-t הקריטיים, אנו נמקם את הערך הt הסטטיסטי באזור הדחייה ונדחה את השערת האפס. כלומר ברמת מובהקות 0.05, אנו נסיק כי ציון הדיוק אכן שונה באופן משמעותי בין שתי שיטות אימון שונות.
כאשר נרצה לבצע רווח סמך באמצעות t למדגם בודד, אנו נשתמש בנוסחה הבאה:

שימו לב שגם כאן כמו ברווח סמך עם טבלת זד, אנחנו חוצים את האלפא. כמו כן, בסוגריים מעל ערך הt, מצוינות דרגות החופש.
ממוצע המדגם:

אומדן לסטיית התקן:

רמת הביטחון הנתונה בשאלה , אחד מינוס אלפא, שווה 95% ולכן רמת המובהקות (המשלימה ל100%, אלפא) היא 5%. מכיוון שמדובר ברווח סמך, אנו חוצים את האלפא ומתייחסים לזנב של 2.5% לכל צד. לכן, בטבלת t נצליב את העמודה של אלפא שווה 2.5% או 0.025 עם השורה של דרגות החופש המתאימות , 11 (12 פחות אחת) ונקבל שערך הt הקריטי הוא פלוס מינוס 2.201 או בכתיב סטטיסטי:

טבלת t:

כעת על שעלינו לעשות הוא להציב בנוסחת הרווח סמך:

בחישוב מהיר נראה שהתוצאה היא שממוצע זמן הנסיעה באמצעות הדרך החדשה באוכלוסייה, ברמת ביטחון של תשעים וחמישה אחוזים נע בין 18.58 ל25.41. במונחים סטטיסטיים נכתוב זאת כך:

כעת זהו השלב שאנו לוקחים את הממצאים שקיבלנו, ונותנים להם פרשנות מילולית. ראינו שתוחלת זמן הנסיעה נע בין 18.58 ל25.41. לכן התשובה תהיה שברמת ביטחון של 95% ניתן לומר שתוחלת זמן הנסיעה יהיה בין 18.58 ל25.41 דקות.
כעת נעבור לחישוב רווח סמך באמצעות שימוש במבחן t למדגמים בלתי תלויים. כאשר נרצה לעשות זאת, נצטרך לעשות שימוש בנוסחה הבאה:

שימו לב שגם כאן נצטרך לחשב את האומדן לסטיית התקן של האוכלוסייה באמצעות אחת משתי הנוסחאות הבאות:

עבור מפעל A:
ממוצע המדגם:

אומדן לסטיית תקן:

עבור מפעל B:
ממוצע המדגם:

אומדן לסטיית תקן:

לאחר מכן, נחשב את סטיית התקן המשותפת על ידי הצבת סטיית התקן של כל מדגם בנוסחה:

כעת, לאחר שחישבנו הנתונים המדגמיים (ממוצעים וסטיות תקן), אפשר להתפנות לחיפוש הערך הקריטי בטבלת t. נתון בשאלה שרמת הביטחון (1–α) היא 99% ולכן אנו מבינים שרמת המובהקות (α) היא 1%. מכיוון שברווח סמך אנו מחלקים את האלפא לכל אחד מהזנבות של ההתפלגות, אנו נחפש את הערך הקריטי שתואם לרמת מובהקות של חצי אלפא או במקרה הנוכחי, חצי אחוז (0.005/0.5%). כמו כן, נסתכל על 20 דרגות חופש (10+12-2) ונמצא את הערך הקריטי ±2.845:

כעת כל שעלינו לעשות הוא להציב בנוסחת הרווח סמך:

לאחר חישוב נקבל:

כעת זהו השלב שאנו לוקחים את הממצאים שקיבלנו, ונותנים להם פרשנות מילולית. ראינו שהפרש תוחלות משקל הגאדג'טים נע בין 0.69- ל2.37 גרם. לכן התשובה תהיה שברמת ביטחון של 99% ניתן לומר שהפרש תוחלות המשקל יהיה בין 0.69- ל2.37 גרם.
כאשר נרצה להשתמש במבחן t למדגמים תלויים לצורך חישוב רווח סמך, נעשה שימוש בנוסחה הבאה:

רווח סמך במבחן t למדגמים מזווגים מייצג את הטווח שבו אנו חושבים שההפרש הממוצע האמיתי בין שתי קבוצות של מדידות עשוי להימצא בו. למשל, רווח סמך של 95% נותן טווח של ערכים שבו אנו בטוחים ב-95% שההפרש הממוצע האמיתי נופל בטווח הזה.
ראשית, עלינו לחשב את ההבדלים במשקל ההרמה לפני ואחרי תוכנית האימון עבור כל חבר. אם נארגן זאת מחדש בטבלה, זה ייראה כך:
מס' חבר | הרמה לפני (ק"ג) | הרמה אחרי (ק"ג) | הפרש |
1 | 100 | 110 | 10 |
2 | 95 | 102 | 7 |
3 | 85 | 92 | 7 |
4 | 110 | 115 | 5 |
5 | 90 | 96 | 6 |
6 | 102 | 108 | 6 |
7 | 97 | 103 | 6 |
8 | 80 | 85 | 5 |
9 | 115 | 118 | 3 |
10 | 100 | 106 | 6 |
לאחר מכן נחשב את הממוצע ואת סטיית התקן של ההפרשים:
ממוצע:

אומדן לסטיית תקן:

מאחר ורמת הביטחון היא 95%, רמת המובהקות שצריכה להשלים ל100%, תהיה 5%. לכן, באמצעות טבלת התפלגות t עם 9 דרגות חופש (n-1) ורמת מובהקות של 2.5% לכל צד, נוכל למצוא כעת את הערך הקריטי: ±2.262

כעת כל שעלינו לעשות הוא להציב בנוסחת הרווח סמך:

לאחר חישוב נקבל:
![]()
כעת זהו השלב שאנו לוקחים את הממצאים שקיבלנו, ונותנים להם פרשנות מילולית. שההפרש (השיפור) הממוצע באוכלוסייה לפני ואחרי יישום שיטת האימון ברמת ביטחון של 95% יהיה בין 4.81 ק"ג ל7.38 ק"ג.